
哔哩哔哩 offer 到手,开出满意的薪资!
面试刷题网站:
大家好,我是小林。
这几天刷到哔哩哔哩 26 届校招开奖啦!不过目前看到的案例不算多,我先收集了三个,都是后端开发的:
后端开发, 27k x 15 = 40.5w
后端开发, 28k x 15 = 42w
后端开发, 29k x 15 = 43.5w
后端开发, 27k x 15 = 40.5w
后端开发, 28k x 15 = 42w
后端开发, 29k x 15 = 43.5w
这薪资是真顶啊,妥妥的大厂 SP 级别!而且还有额外福利,房补加餐补每月大概 1.5k,相当于又省了一笔钱。
想冲 27 届 B 站校招的同学,真心建议明年去 B 站实习,它家转正率挺高的,好多拿到正式 offer 的同学都是实习转过来的。
反观秋招,B 站放出来的面试机会不算多,估计实习转正的名额就差不多能满足招聘需求了,秋招相当于捡漏补录。
前几天帮同学做 offer 选择,他手上有好几个互联网大厂 offer,其中就有 B 站后端的 SP,年薪 42 万 +,薪资这块他是完全满意的。
之前发的面经解析大多是一面,这次咱来看看 B 站今年秋招 Java 二面的面经。
问题不算多,但每个都问得贼细,连 CPU Cache 这种偏底层、大厂考察概率不高的知识点都问到了。最后还甩了道困难级别的算法题,比起一面以基础为主的考察,二面难度明显往上提了一档。
展开全文

哔哩哔哩(Java二面)1. Redis cluster集群原理是什么?
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群(Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步:
根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值。
再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值。
再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
接下来的问题就是,这些哈希槽怎么被映射到具体的 Redis 节点上的呢?有两种方案:
平均分配:在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群节点上。比如集群中有 9 个节点,则每个节点上槽的个数为 16384/9 个。
手动分配:可以使用 cluster meet 命令手动建立节点间的连接,组成集群,再使用 cluster addslots 命令,指定每个节点上的哈希槽个数。
平均分配:在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群节点上。比如集群中有 9 个节点,则每个节点上槽的个数为 16384/9 个。
手动分配:可以使用 cluster meet 命令手动建立节点间的连接,组成集群,再使用 cluster addslots 命令,指定每个节点上的哈希槽个数。
为了方便你的理解,我通过一张图来解释数据、哈希槽,以及节点三者的映射分布关系。
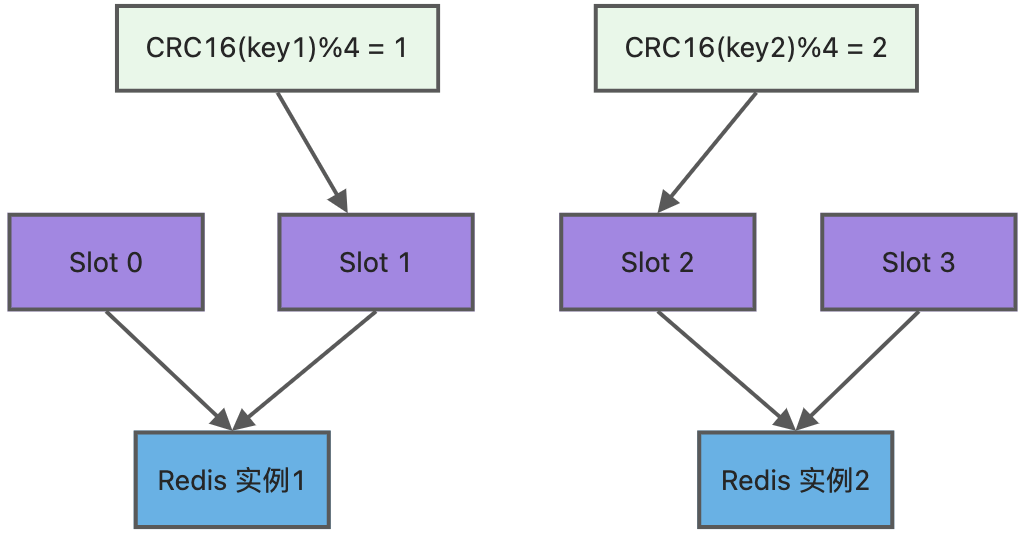
上图中的切片集群一共有 2 个节点,假设有 4 个哈希槽(Slot 0~Slot 3)时,我们就可以通过命令手动分配哈希槽,比如节点 1 保存哈希槽 0 和 1,节点 2 保存哈希槽 2 和 3。
redis-cli -h 192.168.1.10–p 6379cluster addslots 0,1
redis-cli -h 192.168.1.11–p 6379cluster addslots 2,3
然后在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 4 进行取模,再根据各自的模数结果,就可以被映射到哈希槽 1(对应节点1) 和 哈希槽 2(对应节点2)。
需要注意的是,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
2. cluster集群客户端是怎样知道该访问哪个分片的?
首先 Redis Cluster 把所有数据映射到 16384 个哈希槽里,每个集群节点会负责一部分槽位,客户端启动后会先和集群中任意一个节点建立连接,发送CLUSTER SLOTS命令获取全量的 “槽位 - 节点” 映射关系(比如哪些槽位归哪个 IP + 端口的节点管),然后把这份映射关系缓存到本地。
当客户端要访问某个 key 时,会先对 key 做 CRC16 哈希计算,再对 16384 取模,算出这个 key 对应的哈希槽位,接着查本地缓存的映射表,找到该槽位对应的节点地址,直接访问这个节点即可。
如果期间集群节点有变动(比如槽位迁移、节点下线),客户端访问时会收到节点返回的MOVED或ASK重定向指令,客户端会根据指令更新本地的槽位映射缓存,下次再访问这个 key 就会直接找新的节点,不用再重定向。
简单说,客户端先拿全量槽位映射表缓存起来,访问 key 时算槽位、查缓存找节点,遇到变动就更新缓存,全程自动完成,不用开发者手动指定分片,这也是 Redis Cluster 能做到透明分片访问的核心。
3. mysql 事务隔离级别有哪些?
读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
串行化(serializable);会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
串行化(serializable);会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:
针对不同的隔离级别,并发事务时可能发生的现象也会不同。
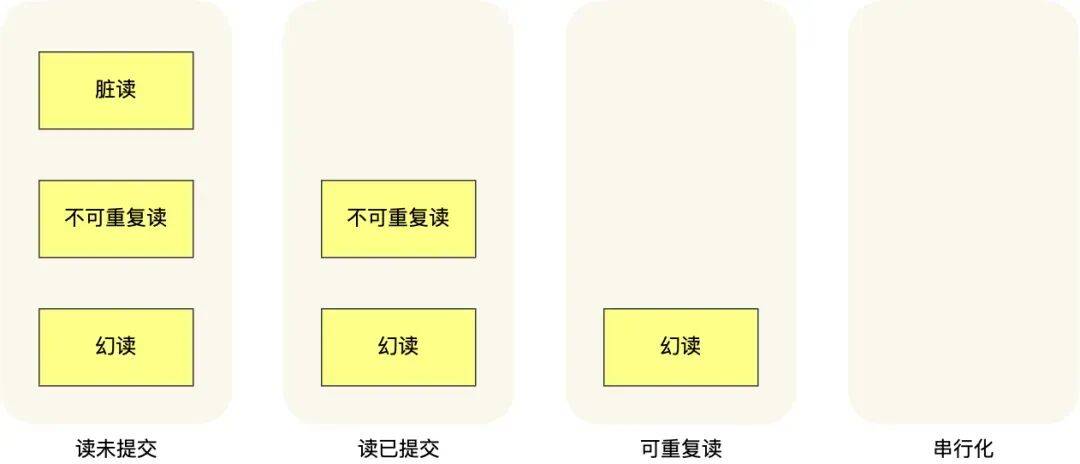
也就是说:
在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
接下来,举个具体的例子来说明这四种隔离级别,有一张账户余额表,里面有一条账户余额为 100 万的记录。然后有两个并发的事务,事务 A 只负责查询余额,事务 B 则会将我的余额改成 200 万,下面是按照时间顺序执行两个事务的行为:
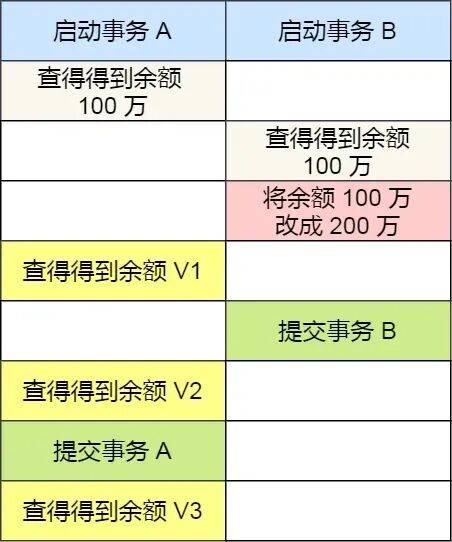
在不同隔离级别下,事务 A 执行过程中查询到的余额可能会不同:
在「读未提交」隔离级别下,事务 B 修改余额后,虽然没有提交事务,但是此时的余额已经可以被事务 A 看见了,于是事务 A 中余额 V1 查询的值是 200 万,余额 V2、V3 自然也是 200 万了;
在「读提交」隔离级别下,事务 B 修改余额后,因为没有提交事务,所以事务 A 中余额 V1 的值还是 100 万,等事务 B 提交完后,最新的余额数据才能被事务 A 看见,因此额 V2、V3 都是 200 万;
在「可重复读」隔离级别下,事务 A 只能看见启动事务时的数据,所以余额 V1、余额 V2 的值都是 100 万,当事务 A 提交事务后,就能看见最新的余额数据了,所以余额 V3 的值是 200 万;
在「串行化」隔离级别下,事务 B 在执行将余额 100 万修改为 200 万时,由于此前事务 A 执行了读操作,这样就发生了读写冲突,于是就会被锁住,直到事务 A 提交后,事务 B 才可以继续执行,所以从 A 的角度看,余额 V1、V2 的值是 100 万,余额 V3 的值是 200万。
在「读未提交」隔离级别下,事务 B 修改余额后,虽然没有提交事务,但是此时的余额已经可以被事务 A 看见了,于是事务 A 中余额 V1 查询的值是 200 万,余额 V2、V3 自然也是 200 万了;
在「读提交」隔离级别下,事务 B 修改余额后,因为没有提交事务,所以事务 A 中余额 V1 的值还是 100 万,等事务 B 提交完后,最新的余额数据才能被事务 A 看见,因此额 V2、V3 都是 200 万;
在「可重复读」隔离级别下,事务 A 只能看见启动事务时的数据,所以余额 V1、余额 V2 的值都是 100 万,当事务 A 提交事务后,就能看见最新的余额数据了,所以余额 V3 的值是 200 万;
在「串行化」隔离级别下,事务 B 在执行将余额 100 万修改为 200 万时,由于此前事务 A 执行了读操作,这样就发生了读写冲突,于是就会被锁住,直到事务 A 提交后,事务 B 才可以继续执行,所以从 A 的角度看,余额 V1、V2 的值是 100 万,余额 V3 的值是 200万。
MySQL 第三范式的核心作用是减少数据冗余、避免更新异常,让数据库表结构更合理、维护更方便,原理其实很简单,就是 “数据只存一次,关联靠主键外键”。
先说说原理,第三范式的定义是 “在满足第二范式(所有字段依赖主键)的基础上,消除传递依赖”。
啥叫传递依赖?就是表中的非主键字段,不直接依赖主键,而是依赖另一个非主键字段。
比如有个 “学生表”,字段是(学生 ID、班级 ID、班级名称),这里 “班级名称” 不直接依赖 “学生 ID”,而是依赖 “班级 ID”,这就是传递依赖。
第三范式就是要把这种传递依赖拆解开,拆成 “学生表(学生 ID、班级 ID)” 和 “班级表(班级 ID、班级名称)”,让 “班级名称” 只存在于班级表中,学生表通过 “班级 ID”(外键)和班级表关联,这样就消除了传递依赖。
再说说作用,最直接的就是减少冗余。
原来每个学生记录都要存一遍班级名称,现在只在班级表存一次,不管多少学生属于同一个班级,都只通过班级 ID 关联,数据量少了,存储空间也省了。
更重要的是避免更新异常,比如要修改班级名称,原来得改所有该班级学生的记录,改的时候可能漏改、错改;现在只需要改班级表中的一条记录,所有关联的学生记录都会通过班级 ID 拿到最新名称,不会出问题。
还有插入和删除异常,比如新增一个班级还没有学生,原来的学生表没法单独存班级信息,拆分后直接插入班级表就行;删除最后一个学生时,也不会把班级名称一起删掉,保证数据的完整性。
不过实际项目中也不会死磕第三范式,比如有些高频查询的场景,为了减少表关联(关联多了会慢),可能会故意保留少量冗余字段,这是性能和范式的权衡。
5. 谈谈你对 Java 多线程的理解?
Java 多线程是指在一个 Java 程序中同时运行多个线程,这些线程共享程序的内存空间(如全局变量、方法区等),但有各自的栈和程序计数器,能同时执行不同的任务,比如一个线程处理用户输入,另一个线程后台下载文件,提升程序效率。
使用 Java 多线程需要注意以下几点:
首先是线程安全问题。多个线程同时操作共享数据时,可能出现错误。比如两个线程同时给一个变量加 1,原本该加 2,结果可能只加了 1,这是因为线程切换时没做好数据保护。需要用synchronized关键字、Lock锁等方式,保证同一时间只有一个线程操作共享数据。
其次是线程间通信。线程需要协作时,比如一个线程生产数据,另一个线程消费数据,要通过wait、notify等方法控制,避免出现一方没准备好,另一方就操作的情况,否则可能导致数据错误或线程无限等待。
然后是线程的创建和销毁成本。频繁创建和销毁线程会消耗系统资源,影响性能。可以用线程池管理线程,提前创建好一定数量的线程,重复使用,减少资源消耗。
首先是线程安全问题。多个线程同时操作共享数据时,可能出现错误。比如两个线程同时给一个变量加 1,原本该加 2,结果可能只加了 1,这是因为线程切换时没做好数据保护。需要用synchronized关键字、Lock锁等方式,保证同一时间只有一个线程操作共享数据。
其次是线程间通信。线程需要协作时,比如一个线程生产数据,另一个线程消费数据,要通过wait、notify等方法控制,避免出现一方没准备好,另一方就操作的情况,否则可能导致数据错误或线程无限等待。
然后是线程的创建和销毁成本。频繁创建和销毁线程会消耗系统资源,影响性能。可以用线程池管理线程,提前创建好一定数量的线程,重复使用,减少资源消耗。
CPU Cache 的缓存行其实就是 CPU 缓存(L1/L2/L3)存储数据的「最小单位」,简单说就是缓存里的 “存储块”。
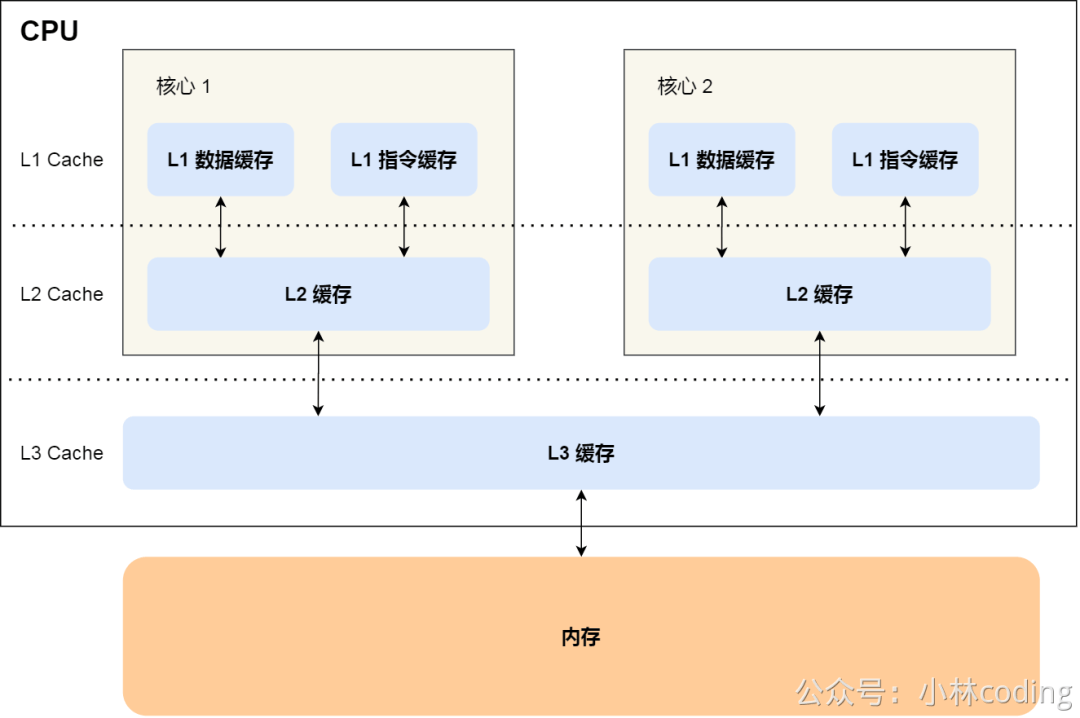
CPU 访问内存的速度特别慢,比访问自身缓存慢几十到上百倍,所以会把内存中常用的数据加载到缓存里,下次再访问就直接从缓存拿,提升速度。但缓存不是按单个字节加载的,而是一次性加载一块连续的内存数据,这块 “一次性加载的连续数据块” 就是缓存行,常见大小是 64 字节(少数是 32 字节)。
比如你要访问内存中一个 int 类型的数据(4 字节),CPU 不会只加载这 4 字节,而是会把它旁边的 60 多字节数据一起加载到同一个缓存行里。这是因为程序运行时数据访问有 “局部性”, 比如数组遍历、连续结构体访问,大概率会用到相邻的数据,一次性加载能减少后续访问内存的次数,进一步提升效率。
不过这也会带来 “伪共享” 问题:如果两个不相关的变量刚好在同一个缓存行里,一个 CPU 核心修改其中一个变量,会导致整个缓存行失效,另一个核心访问另一个变量时,就只能重新从内存加载,反而拖慢速度。所以实际编程中,会用 “缓存行填充”(比如加无用字段凑够 64 字节)避免这种情况,让关键变量各自独占一个缓存行。
7. 伪共享是什么?
接下来,就来看看 Cache 伪共享是什么?又如何避免这个问题?
现在假设有一个双核心的 CPU,这两个 CPU 核心并行运行着两个不同的线程,它们同时从内存中读取两个不同的数据,分别是类型为 long的变量 A 和 B,这个两个数据的地址在物理内存上是连续的,如果 Cahce Line 的大小是 64 字节,并且变量 A 在 Cahce Line 的开头位置,那么这两个数据是位于同一个 Cache Line 中,又因为 CPU Line 是 CPU 从内存读取数据到 Cache 的单位,所以这两个数据会被同时读入到了两个 CPU 核心中各自 Cache 中。
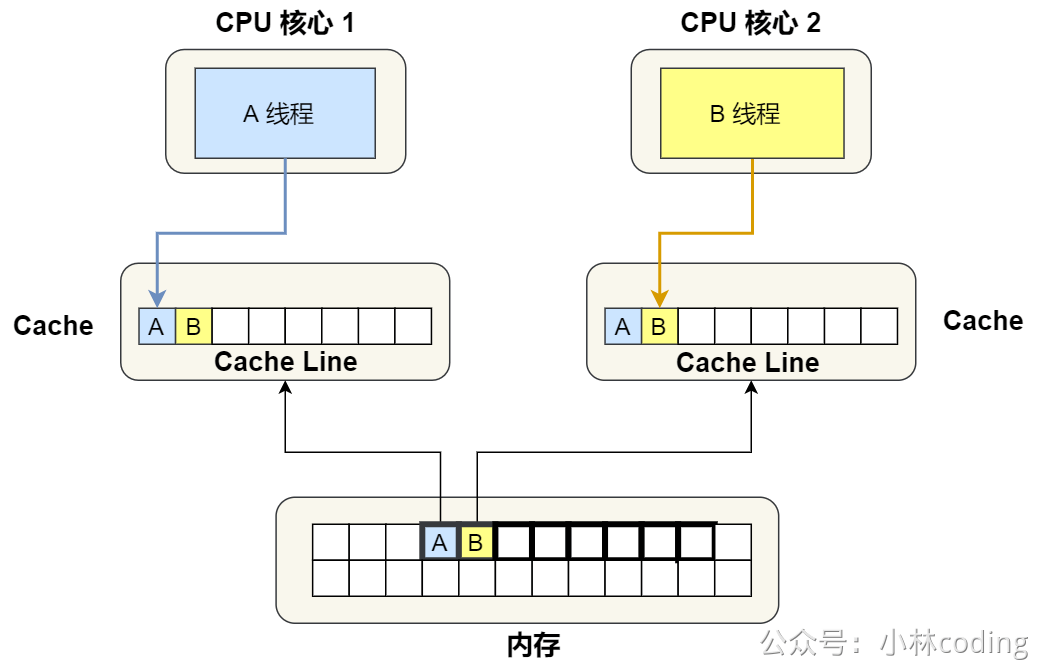
我们来思考一个问题,如果这两个不同核心的线程分别修改不同的数据,比如 1 号 CPU 核心的线程只修改了 变量 A,或 2 号 CPU 核心的线程的线程只修改了变量 B,会发生什么呢?
现在我们结合保证多核缓存一致的 MESI 协议,来说明这一整个的过程,如果你还不知道 MESI 协议,你可以看我这篇文章「」。
①. 最开始变量 A 和 B 都还不在 Cache 里面,假设 1 号核心绑定了线程 A,2 号核心绑定了线程 B,线程 A 只会读写变量 A,线程 B 只会读写变量 B。
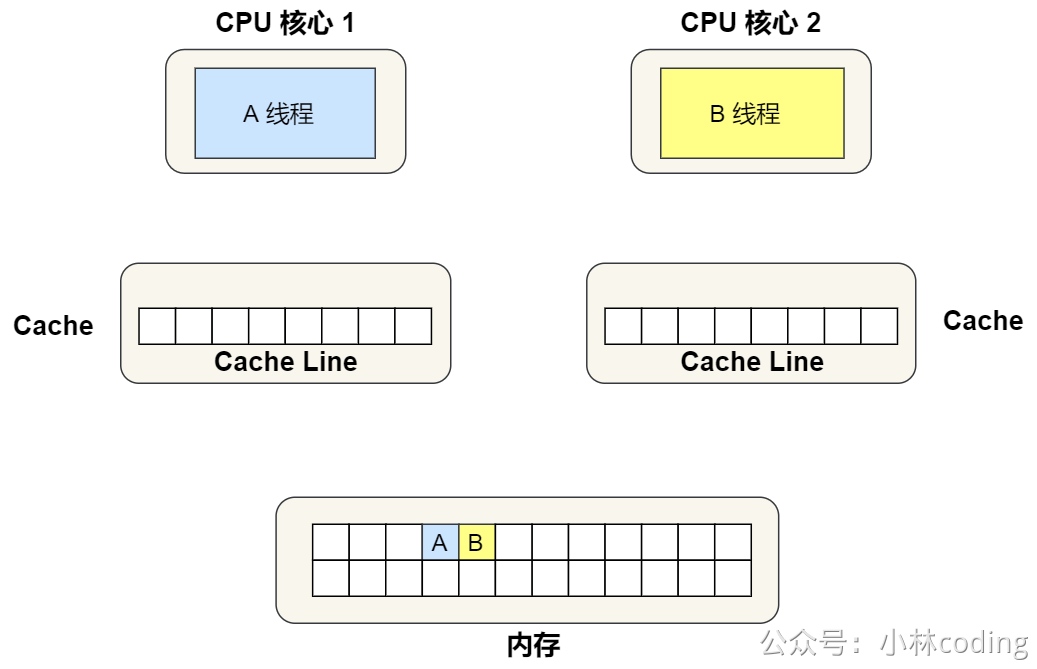
②. 1 号核心读取变量 A,由于 CPU 从内存读取数据到 Cache 的单位是 Cache Line,也正好变量 A 和 变量 B 的数据归属于同一个 Cache Line,所以 A 和 B 的数据都会被加载到 Cache,并将此 Cache Line 标记为「独占」状态。
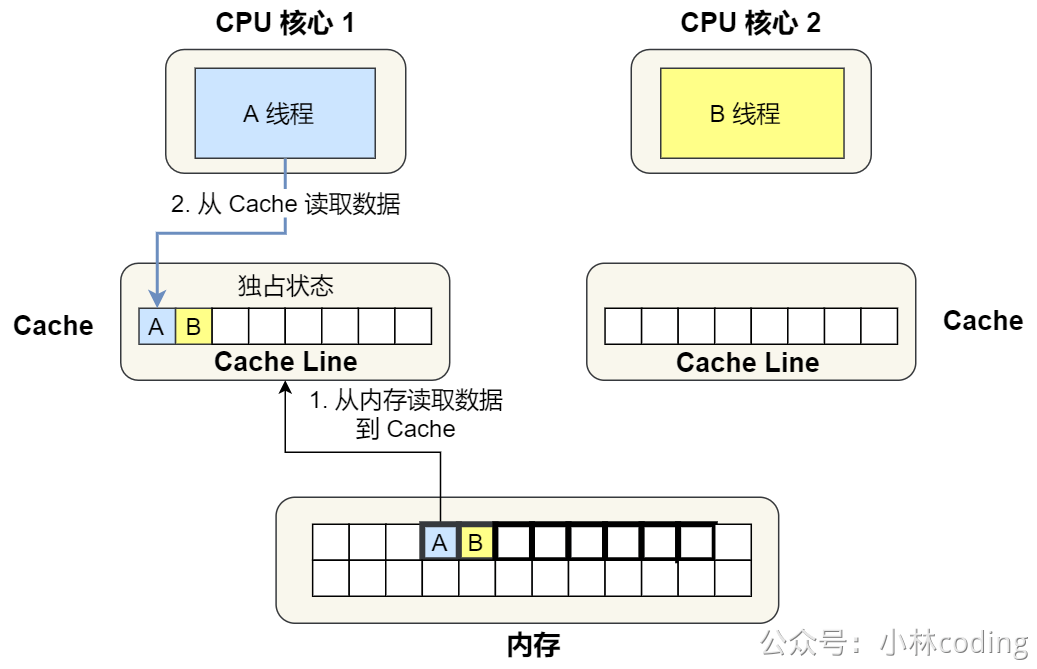
③. 接着,2 号核心开始从内存里读取变量 B,同样的也是读取 Cache Line 大小的数据到 Cache 中,此 Cache Line 中的数据也包含了变量 A 和 变量 B,此时 1 号和 2 号核心的 Cache Line 状态变为「共享」状态。
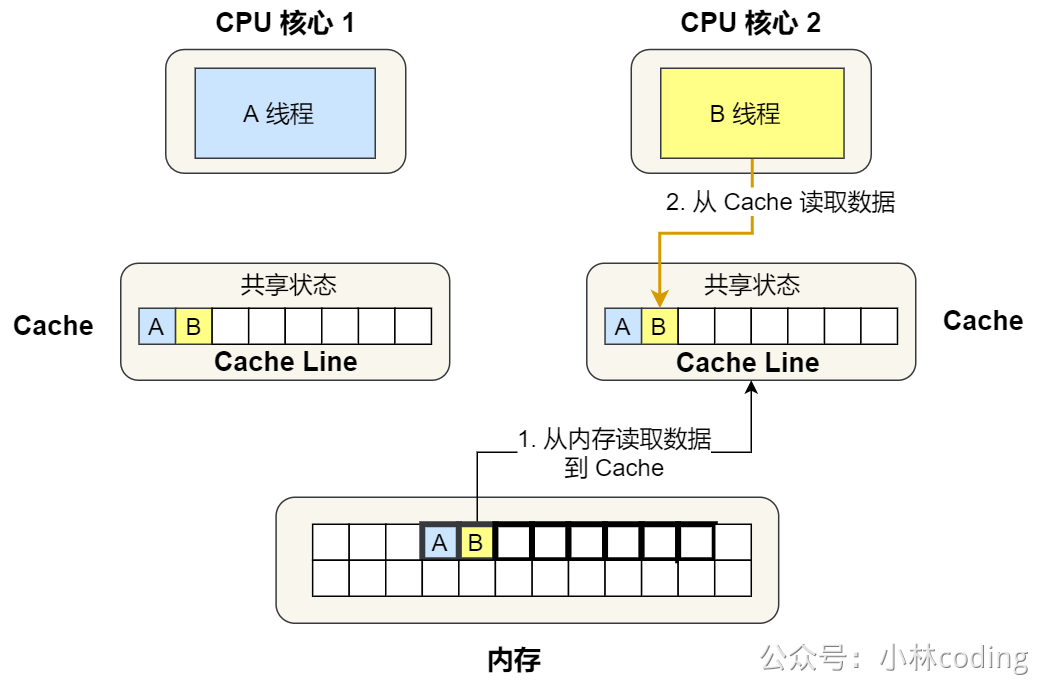
④. 1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。
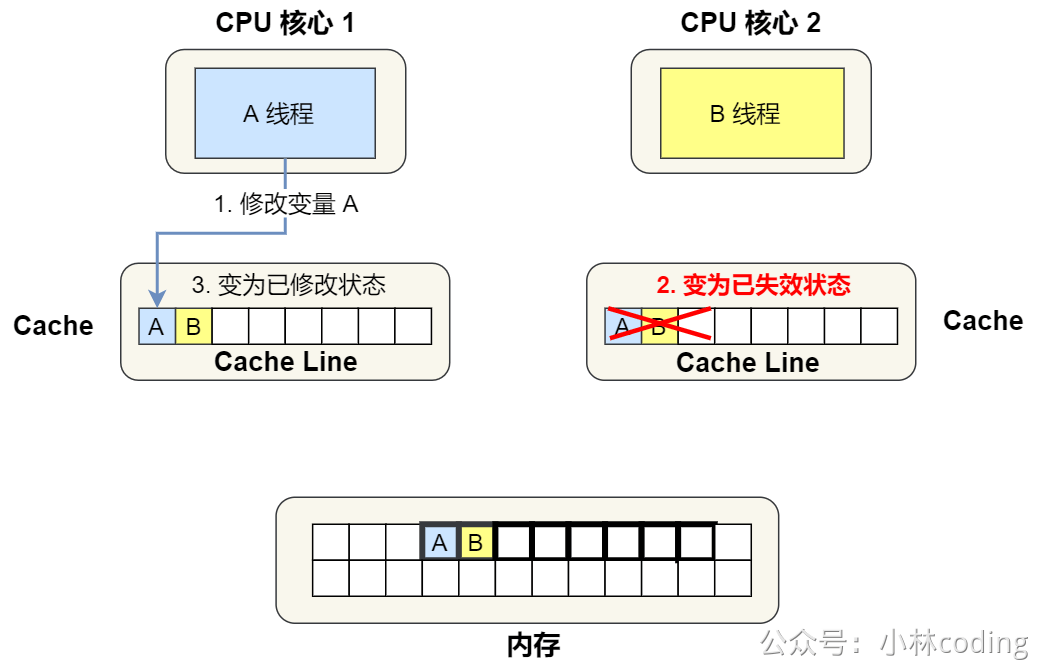
⑤. 之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。
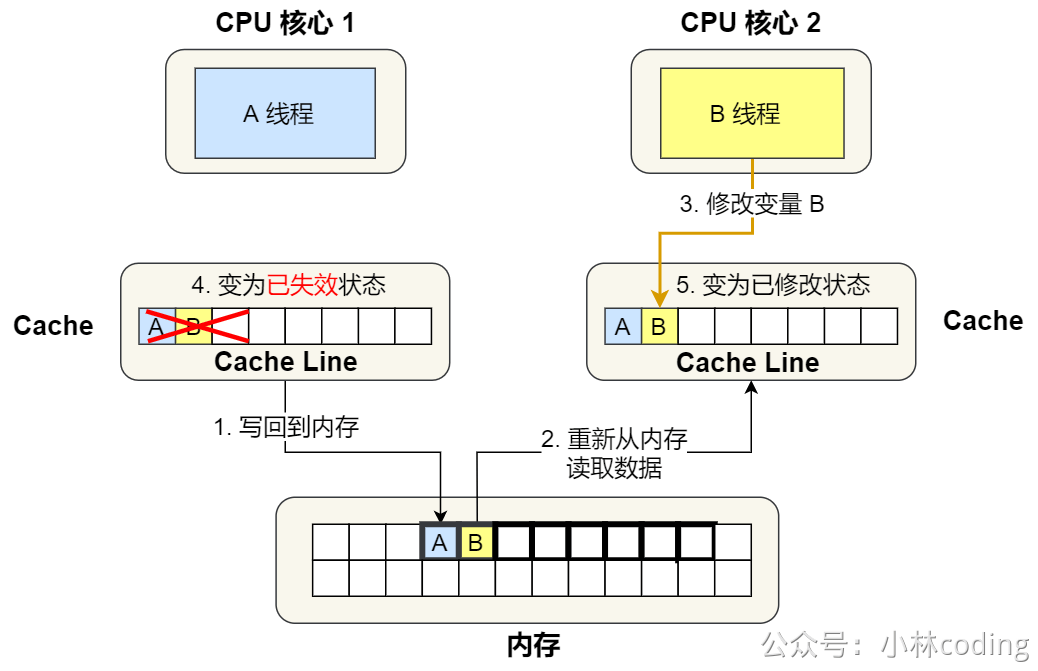
所以,可以发现如果 1 号和 2 号 CPU 核心这样持续交替的分别修改变量 A 和 B,就会重复 ④ 和 ⑤ 这两个步骤,Cache 并没有起到缓存的效果,虽然变量 A 和 B 之间其实并没有任何的关系,但是因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响,从而出现 ④ 和 ⑤ 这两个步骤。
因此,这种因为多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(False Sharing)。
8. BIO,NIO的原理与区别
两者的核心区别很明显:BIO 是阻塞的,一个连接一个线程,并发能力差;NIO 是非阻塞的,靠 Selector 多路复用,一个线程能管很多连接,并发效率高。
先说说 BIO,也就是阻塞 I/O。它的原理特别简单,就是 “一个连接对应一个线程”。
比如服务器端要处理客户端连接,每来一个客户端,就得新建一个线程去处理它的读写请求,而且线程在等待数据(比如客户端发数据、网络传输)的时候,会一直阻塞着,啥也干不了,直到数据就绪才能继续执行。
比如以前写 Socket 编程,用 ServerSocket.accept 等待连接,用 InputStream.read 读数据,这些方法都是阻塞的,线程会卡在那儿。这种模式的问题很明显,要是有上万个客户端连接,就得开上万个线程,线程切换和资源占用都会把服务器拖垮,只能适用于连接数少、并发低的场景,比如早期的简单服务。
再看 NIO,也就是非阻塞 I/O,它是 Java 1.4 之后出的,专门解决 BIO 的并发问题。核心原理是 “非阻塞 + 多路复用”,首先它的 Socket 是可以设置为非阻塞的。
线程发起读写请求后,不会一直等着,要是数据没就绪,就直接返回,线程可以去处理其他事情,不用空等;然后关键是 “多路复用器”(Selector),这个东西就像一个 “交通指挥员”,一个线程就能管理成百上千个 Socket 连接,它会不断轮询这些连接,看看哪些连接的数据就绪了(比如有数据可以读、可以写),然后通知线程去处理这些就绪的连接。
比如服务器端启动一个 Selector,把所有 Socket 通道注册到 Selector 上,线程只需要调用 Selector.select 等待就绪事件,一旦有连接就绪,就批量处理这些连接的读写,不用给每个连接开线程。
9. 算法
hard(股票最佳时机Ⅲ)
hard(股票最佳时机Ⅲ)
相关文章
-

巴基斯坦总理访华第2天,开口就是要成为南亚的“小中国”
-
25岁海归男子恋上浙江离异老板娘,分手后追讨12万:每个月给她点外卖都要五六千,对方却没转过一分钱,每次转账还要写自愿赠与,准备起诉
-
“给我500元,否则继续投诉你!”浙江一快递员送错的快递疑被转手寄走,找收件人沟通却屡遭投诉,连民警和记者也都被投诉
-
伊朗:击落“死神”,并向F-35开火!最高领袖穆杰塔巴:美国在中东的地位将不复存在,伊朗及盟友取得显著胜利
-
市值蒸发近70亿,投资者发起索赔,巨力索具怎么了?
-
7天狂卖1吨!上海阿姨爷叔排长队也要买,“这酱特别香,吃了让人难忘!”
-
中超联赛第13轮比赛,北京国安客场1比1战平青岛西海岸
-
中央生态环保督察组:齐齐哈尔湿地破坏严重 人为造成湿地减少2700余亩








评论